The minimum connector problem gives a way to join every vertex in a network so that the total weight of the edges used is minimised.
Figure 1: Roads connecting towns in southern England
The towns in southern England are to be connected with a new fibre-optic cable system. The hub of the system is to be in London. What is the minimum length of cable needed to connect the towns?
There are two algorithms that we can use to solve this type of problem:
Kruskal’s algorithm finds the minimum spanning tree for a network.
Kruskal’s algorithm has the following steps:
Select the edge with the lowest weight that does not create a cycle. If there are two or more edges with the same weight choose one arbitrarily.
Repeat step 1 until the graph is connected and a tree has been formed.
Example
Finding the minimum spanning tree that follows the road network in southern England
Using Kruskal’s algorithm the minimum spanning tree is generated as follows (each selected edge is coloured red). Click or tap an image for a larger view.
Figure 1: Roads connecting towns in southern England
Figure 2: Kruskal solution step 1
Figure 3: Kruskal solution step 2
Figure 4: Kruskal solution step 3
Figure 5: Kruskal solution step 4
Figure 6: Kruskal solution step 5
The solution for the minimum spanning tree contains the edges {(Bristol, Swindon), (Swindon, Oxford), (Oxford, Reading), (Reading, London), (Reading, Southampton)}. The total weight (distance) for the minimum solution is .
Prim’s algorithm generates a minimum spanning tree for a network. Prim’s algorithm has the following steps:
Select any vertex. Connect the nearest vertex.
Find the vertex that is nearest to the current tree but not already connected and connect that.
Repeat step 2 until all vertices are connected.
Often, assuming that you are doing this for the purposes of an exam, you will be told the starting vertex for step 1. If you find that there is more than one vertex equally close in step 2, choose one arbitrarily.
Example
Finding the minimum spanning tree that follows the road network in southern England.
Using Prim’s algorithm the minimum spanning tree is generated as follows (each selected edge and node is coloured red). Click or tap an image for a larger view.
Figure 1: simplified road network of southern England, Swindon selected as a start point.
Figure 2: Prim’s algorithm step 1, connecting Swindon to Oxford, the nearest adjacent node.
Figure 3: Prim’s algorithm step 2, connecting Oxford to Reading, the nearest node not already in the tree.
Figure 4: Prim’s algorithm step 2, connecting Swindon to Bristol, the nearest node not already in the tree. Bristol was chosen arbitrarily at this point, but London is the same distance and could have equally have been chosen.
Figure 5: Prim’s algorithm step 2, connecting Reading to London, the nearest node not already in the tree.
Figure 6: Prim’s algorithm step 2, connecting Reading to Southampton, the nearest node not already in the tree.
The solution contains the following edges {(Bristol, Swindon), (Swindon, Oxford), (Oxford, Reading), (Reading, London), (Reading, Southampton)} and the total weight (distance) for the minimum solution is .
Other points to note
Prim’s Algorithm also has a table-based form that can easily be applied to matrices or distance tables. This means that it is particularly suited for applying to a computerised solution.
Due to the number of comparisons of weight needed at each iteration, Prim’s Algorithm is .
Prim’s algorithm is also suitable for use on distance tables or matrices, or the equivalent for the problem. This is useful for large problems where drawing the network diagram would be hard or time-consuming.
That tables can be used makes the algorithm more suitable for automation than Kruskal’s algorithm. The reason for this is that the data used would have to be sorted to be used with Kruskal’s algorithm. With Prim’s algorithm, however, it is only the minimum value that is of interest, so no sorting is normally necessary.
We will look again at our question that requires a minimum spanning tree for the network of towns in the south of England using main road connections. The network diagram is as shown in figure 1.
Figure 1: Network of road connections in southern England.
The network shown in Figure 1 can be represented by the adjacency matrix shown in Table 1.
Bristol
London
Oxford
Reading
Southampton
Swindon
Bristol
–
×
×
×
75
40
London
×
–
60
40
×
70
Oxford
×
60
–
27
×
30
Reading
×
40
27
–
42
45
Southampton
75
×
×
42
–
70
Swindon
40
70
30
45
70
–
Table 1: tabular version of road network. × means no direct link.
The tabular form of Prim’s algorithms has the following steps:
Select any vertex (town). Cross out its row. Select the shortest distance (lowest value) from the column(s) for the crossed out row(s). Highlight that value.
Cross out the row with the newly highlighted value in. Repeat step 1. Continue until all rows are crossed out.
Once all rows are crossed out, read off the connections. The column and the row of each highlighted value are the vertices that are linked and should be included.
Example
First we will choose a town at random – Swindon – and cross out that row. Then we highlight the smallest value in the column for the crossed out row.
Bristol
London
Oxford
Reading
Southampton
Swindon
Bristol
–
×
×
×
75
40
London
×
–
60
40
×
70
Oxford
×
60
–
27
×
30
Reading
×
40
27
–
42
45
Southampton
75
×
×
42
–
70
Swindon
40
70
30
45
70
–
Table 2: Prim’s algorithm first iteration.
Next we need to cross out the row with the newly-highlighted value in (the Oxford row). Then we look for, and highlight, the smallest value in the columns for the two crossed out rows (Swindon and Oxford).
Bristol
London
Oxford
Reading
Southampton
Swindon
Bristol
–
×
×
×
75
40
London
×
–
60
40
×
70
Oxford
×
60
–
27
×
30
Reading
×
40
27
–
42
45
Southampton
75
×
×
42
–
70
Swindon
40
70
30
45
70
–
Table 3: Prim’s algorithm second iteration.
Next we need to cross out the row with the newly-highlighted value in (the Reading row). Then we look for, and highlight, the smallest value in the columns for the three crossed out rows (Swindon, Oxford, and Reading).
Bristol
London
Oxford
Reading
Southampton
Swindon
Bristol
–
×
×
×
75
40
London
×
–
60
40
×
70
Oxford
×
60
–
27
×
30
Reading
×
40
27
–
42
45
Southampton
75
×
×
42
–
70
Swindon
40
70
30
45
70
–
Table 4: Prim’s algorithm third iteration.
Next we need to cross out the row with the newly-highlighted value in (the Bristol row). Then we look for, and highlight, the smallest value in the columns for the four crossed out rows (Swindon, Oxford, Reading, and Bristol).
Bristol
London
Oxford
Reading
Southampton
Swindon
Bristol
–
×
×
×
75
40
London
×
–
60
40
×
70
Oxford
×
60
–
27
×
30
Reading
×
40
27
–
42
45
Southampton
75
×
×
42
–
70
Swindon
40
70
30
45
70
–
Table 5: Prim’s algorithm fourth iteration.
Next we need to cross out the row with the newly-highlighted value in (the London row). Then we look for, and highlight, the smallest value in the columns for the crossed out rows (Swindon, Oxford, Reading, Bristol, and Southampton).
Bristol
London
Oxford
Reading
Southampton
Swindon
Bristol
–
×
×
×
75
40
London
×
–
60
40
×
70
Oxford
×
60
–
27
×
30
Reading
×
40
27
–
42
45
Southampton
75
×
×
42
–
70
Swindon
40
70
30
45
70
–
Table 6: Prim’s algorithm fifth and final iteration.
We’ve now selected a value from the last undeleted row. This means we’ve selected all the edges that we need to create the minimum spanning tree for the network. All we have left to do is write out the connections between the vertices.
The connections in the network are found by taking the row and column headings for each selected value in the table. The edges are: {(Bristol, Swindon), (London, Reading), (Oxford, Swindon), (Reading, Oxford), (Southampton, Reading)}. This is the set of edges as in the minimum spanning tree generated by the diagrammatic version of the algorithm.
The second problem that we will consider for networks is that of finding the shortest route between any two vertices in the network. As the name suggests the shortest route problem is most commonly applied to transport networks. Other applications include, for example, cost minimisation. Although there are a number of algorithms that are designed to find minimum cost routes between vertices in a network the only algorithm with which you need to be familiar at A Level is Dijkstra’s algorithm.
Dijkstra’s algorithm generates the shortest path tree from a given node to any (or every) other node in the network.
Although the problem that we will use as an example is fairly trivial and can be solved by inspection, the technique that we will use can be applied to much larger problems.
Dijkstra’s algorithm requires that each node in the network be assigned values (labels). There is a working label and a permanent label, as well as an ordering label. Whilst going through the steps of the algorithm you will assign a working label to each vertex. The smallest working label at each iteration will become permanent.
The steps of Dijkstra’s algorithm are:
Give the start point the permanent label of 0, and the ordering label 1.
Any vertex directly connected to the last vertex given a permanent label is assigned a working label equal to the weight of the connecting edge added to the permanent label you are coming from. If it already has a working label replace it only if the new working label is lower.
Select the minimum current working value in the network and make it the permanent label for that node.
If the destination node has a permanent label go to step 5, otherwise go to step 2.
Connect the destination to the start, working backwards. Select any edge for which the difference between the permanent labels at each end is equal to the weight of the edge.
It is a good idea to use a system for keeping track of the current working labels and the ordering and permanent labels of each of the nodes in the network. A standard system found on A Level exams is that a small grid is drawn near each of the nodes, working labels are written in the lower box, ordering labels in the upper left box, and permanent labels in the upper right box, as shown in figure 1.
Figure 1: Labelling system for Dijkstra’s Algorithm.
Example
In this example we will consider the network in figure 2. We would like to find the shortest path from node A to node H.
Figure 2: A simple network.The first four steps of the algorithm are completed.
As you can see at the end of the video, the destination node (node H) has a permanent label. This means that a shortest route from A to H has been found.
The shortest route is found by tracing back from the destination node (node H) to the start (node A), selecting each edge for which the difference between permanent values at its terminating nodes is equal to the weight of the edge. The shortest routes for this network are shown in figure 3 below. The edges shown in green (AB and BC) are an alternative to the edge AC shown in red. In this case there are two equivalent shortest routes from A to H.
Figure 3: The shortest routes from A to H in this network.
The solution to the shortest route problem, from A to H, in this network is therefore A-C-G-H, or the equivalent distance A-B-C-G-H. Both have a total distance of 11 units, given by the permanent label of the terminal node.
The complexity of an algorithm is a measure of the amount of work required to complete the algorithm in the worst case scenario. When we are looking at networks, the worst case is generally given by a complete network. Remember that a complete network has every node directly connected to every other node in the network.
The degree of complexity of an algorithm tells you how much extra work would need to be done if the problem were to be increased in size.
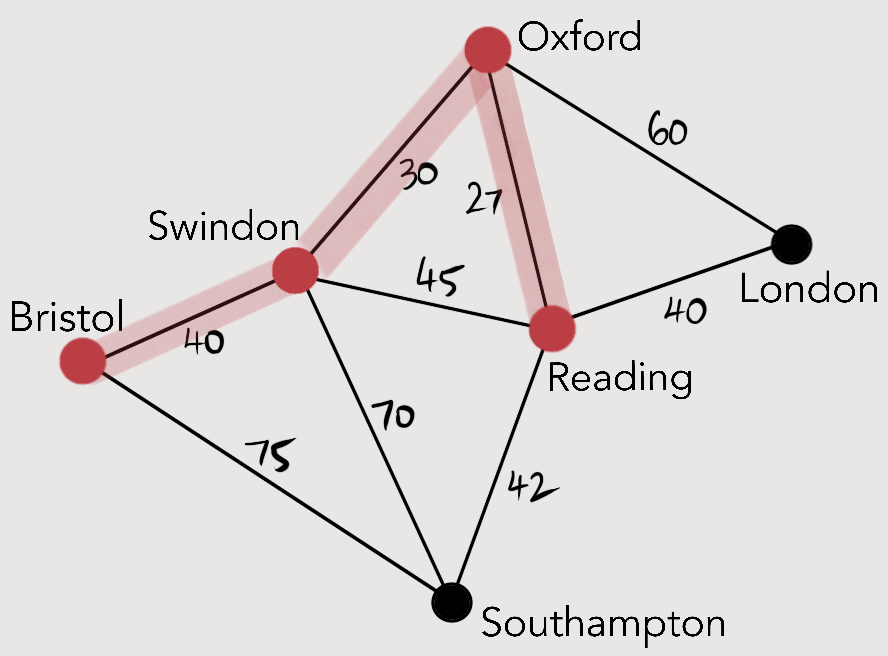
Constant complexity, , means that the amount of work is constant, and is independent of the size of the problem.
Linear complexity, , means that if the problem doubles in size, there will be double the work to do.
Quadratic complexity, , indicates that there will be four times the amount of work if the size of the problem is doubled.
Exponential, logarithmic and many other degrees of complexity are possible based on the size and runtime of the algorithm.
In Kruskal’s algorithm we need to find edge with the lowest weight at each step. Taking the worst case of a complete network there will be edges, which is equal to possible edges. Inspecting each edge to determine the one with the lowest weight is the most time consuming job so the number of inspections to complete the problem will give an indication of the complexity of the algorithm.
In the first round of inspections, all of the edges need to be inspected and compared. There will be comparisons to make.
In the second round of inspections, all of the edges, except the one already selected, need to be inspected and compared. There will be comparisons to make.
In a spanning tree for a network with nodes, there will be edges that will have to be selected. This would require the following number of comparisons to be made in total:
After messing about with all of the algebra you discover that this can also be written as: . It follows that Kruskal’s algorithm has cubic complexity.
Prim’s algorithm starts by selecting the least weight edge from one node. In a complete network there are edges from each node.
At step 1 this means that there are comparisons to make.
Having made the first comparison and selection there are unconnected nodes, with a edges joining from each of the two nodes already selected. This means that there are comparisons that need to be made.
Carrying on this argument results in the following expression for the number of comparisons that need to be made to complete the minimum spanning tree:
Dijkstra’s algorithm inspects each of the nodes that have not yet been permanently labelled, so the work per step is approximately proportional to the number of remaining nodes. For the entire process this number is: .








 .
.




 .
.



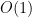 , means that the amount of work is constant, and is independent of the size of the problem.
, means that the amount of work is constant, and is independent of the size of the problem.  , means that if the problem doubles in size, there will be double the work to do.
, means that if the problem doubles in size, there will be double the work to do.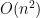 , indicates that there will be four times the amount of work if the size of the problem is doubled.
, indicates that there will be four times the amount of work if the size of the problem is doubled. edges, which is equal to
edges, which is equal to ![\frac{1}{2}[n(n + 1)]](http://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D&bg=ffffff&fg=000&s=0&c=20201002) possible edges. Inspecting each edge to determine the one with the lowest weight is the most time consuming job so the number of inspections to complete the problem will give an indication of the complexity of the algorithm.
possible edges. Inspecting each edge to determine the one with the lowest weight is the most time consuming job so the number of inspections to complete the problem will give an indication of the complexity of the algorithm. ![\frac{1}{2}[n(n + 1)] - 1](http://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+1&bg=ffffff&fg=000&s=0&c=20201002) comparisons to make.
comparisons to make.![\frac{1}{2}[n(n + 1)] - 2](http://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+2&bg=ffffff&fg=000&s=0&c=20201002) comparisons to make.
comparisons to make. nodes, there will be
nodes, there will be  edges that will have to be selected. This would require the following number of comparisons to be made in total:
edges that will have to be selected. This would require the following number of comparisons to be made in total:![{\frac{1}{2}[n(n + 1)] - 1} + {\frac{1}{2}[n(n + 1)] - 2} + {\frac{1}{2}[n(n + 1)] - 3} + \dotsc + {\frac{1}{2}[n(n + 1)] - (n - 1)}](http://s0.wp.com/latex.php?latex=%7B%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+1%7D+%2B+%7B%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+2%7D+%2B+%7B%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+3%7D+%2B+%5Cdotsc+%2B+%7B%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+%28n+-+1%29%7D&bg=ffffff&fg=000&s=0&c=20201002)
 . It follows that Kruskal’s algorithm has cubic complexity.
. It follows that Kruskal’s algorithm has cubic complexity. comparisons to make.
comparisons to make. unconnected nodes, with a edges joining from each of the two nodes already selected. This means that there are
unconnected nodes, with a edges joining from each of the two nodes already selected. This means that there are  comparisons that need to be made.
comparisons that need to be made.
 .
.