
The complexity of an algorithm is a measure of the amount of work required to complete the algorithm in the worst case scenario. When we are looking at networks, the worst case is generally given by a complete network. Remember that a complete network has every node directly connected to every other node in the network.
The degree of complexity of an algorithm tells you how much extra work would need to be done if the problem were to be increased in size.
Constant complexity, 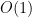
Linear complexity, 
Quadratic complexity, 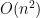
Exponential, logarithmic and many other degrees of complexity are possible based on the size and runtime of the algorithm.
 edges, which is equal to
edges, which is equal to ![\frac{1}{2}[n(n + 1)]](http://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D&bg=ffffff&fg=000&s=0&c=20201002) possible edges. Inspecting each edge to determine the one with the lowest weight is the most time consuming job so the number of inspections to complete the problem will give an indication of the complexity of the algorithm.
possible edges. Inspecting each edge to determine the one with the lowest weight is the most time consuming job so the number of inspections to complete the problem will give an indication of the complexity of the algorithm. ![\frac{1}{2}[n(n + 1)] - 1](http://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+1&bg=ffffff&fg=000&s=0&c=20201002) comparisons to make.
comparisons to make.![\frac{1}{2}[n(n + 1)] - 2](http://s0.wp.com/latex.php?latex=%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+2&bg=ffffff&fg=000&s=0&c=20201002) comparisons to make.
comparisons to make. nodes, there will be
nodes, there will be  edges that will have to be selected. This would require the following number of comparisons to be made in total:
edges that will have to be selected. This would require the following number of comparisons to be made in total:![{\frac{1}{2}[n(n + 1)] - 1} + {\frac{1}{2}[n(n + 1)] - 2} + {\frac{1}{2}[n(n + 1)] - 3} + \dotsc + {\frac{1}{2}[n(n + 1)] - (n - 1)}](http://s0.wp.com/latex.php?latex=%7B%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+1%7D+%2B+%7B%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+2%7D+%2B+%7B%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+3%7D+%2B+%5Cdotsc+%2B+%7B%5Cfrac%7B1%7D%7B2%7D%5Bn%28n+%2B+1%29%5D+-+%28n+-+1%29%7D&bg=ffffff&fg=000&s=0&c=20201002)
 . It follows that Kruskal’s algorithm has cubic complexity.
. It follows that Kruskal’s algorithm has cubic complexity. comparisons to make.
comparisons to make. unconnected nodes, with a edges joining from each of the two nodes already selected. This means that there are
unconnected nodes, with a edges joining from each of the two nodes already selected. This means that there are  comparisons that need to be made.
comparisons that need to be made.
 .
.